Множини
Множини
Множини в Python — змінюваний тип даних, який являє собою масив елементів, що не повторюються.
Тому, щоби познайомитись із ними ближче, створимо новий проєкт на replit.com в якому пропишемо:
our_set = set()
our_set_2 = {0}
print(our_set, type(our_set))
print(our_set_2, type(our_set_2))

Запустимо код (відео 1):
Відео 1
Як бачимо, ми створили множини двома різними способами. Але є нюанси.За першого способу створення множини, необхідно залишати дужки пустими або вставляти ітерований елемент, тобто елемент, що є масивом даних. Це може бути список або рядок, причому, якщо передати рядок, то він буде розбитий на знаки. Використовуючи другий спосіб важливо, щобипід час створення множини всередину був поміщений як мінімум один елемент. Інакше буде створено елемент типу «словник», з яким ми познайомимось наступного заняття. Створивши множини, саме час їх наповнити, у чому допоможе метод add(). Запишемо:
our_set = set()
our_set_2 = {0}
our_set.add("tomato")
our_set_2.add("potato")
print(our_set)
print(our_set_2)
Отримаємо (відео 2):
Відео 2
Аналогічно до попередніх типів даних, можна дізнатися кількість елементів з допомогою функції len() (відео 3):
Відео 3
А як дізнатись чи є елемент в множині? Наприклад, перевірити наявність змінної х у наших множинах можна скориставшись синтаксисом:
our_set = set()
our_set_2 = {0}
x = "tomato"
our_set.add("tomato")
our_set_2.add("potato")
print(x in our_set)
print(x in our_set_2)
Запустимо код (відео 4):
Відео 4
Як бачимо, у першому випадку повернулося значення True, отже, елемент присутній. Коли елемент відсутній, повертається значення False, як у другому випадку.
Щоби краще уявляти собі множини, зобразимо їх у вигляді кругів (мал. 1).
Малюнок 1
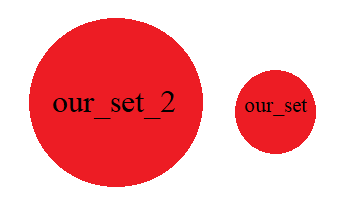
Оскільки множина our_set_2 більша за our_set, то і круг її буде більшим. Як бачимо, зараз наші множини мирно співіснують поряд, не торкаючись і не перетинаючи одна одну, а отже не мають спільних елементів. Впевнитись в цьому можна з допомогою методу isdisjoint(), що повертає значення True, якщо у множин немає спільних елементів:
our_set = set()
our_set_2 = {0}
our_set.add("tomato")
our_set_2.add("potato")
print(our_set.isdisjoint(our_set_2))
Результат (відео 5):
Відео 5
Не дивлячись на відсутність спільних елементів, множину можна розширити з допомогою методу update() або ж об'єднати множини методом union(), записавши їх до окремої змінної:
our_set = set()
our_set_2 = {0}
our_set.add("tomato")
our_set_2.add("potato")
our_set_3 = our_set.union(our_set_2)
our_set.update(our_set_2)
print(our_set_3)
print(our_set)
Запустимо код (відео 6):
Відео 6
Ось як виглядають ці операції (мал. 2):
Малюнок 2
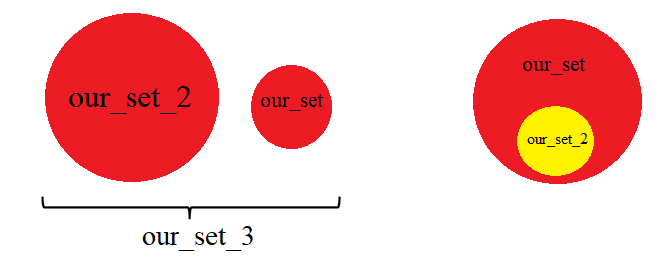
Як бачимо, множина може містити в собі іншу множину, а для перевірки цього використовують метод issubset(), що повертає значення True, якщо всі елементи множини належать множині всередині дужок. Якщо ж необхідно перевірити чи належить множина всередині дужок множині, що викликає метод, використовується метод issuperset(). Перевіримо, записавши:
our_set = set()
our_set_2 = {0}
our_set.add("tomato")
our_set_2.add("potato")
our_set_3 = our_set.union(our_set_2)
our_set.update(our_set_2)
print(our_set_2.issubset(our_set_3))
print(our_set_3.issuperset(our_set_2))
Маємо (відео 7):
Відео 7
Інвестор
А тепер, уявимо, що ми інвестори.
У нас є перелік товарів, у які ми вкладаємо кошти, вони знаходяться в множині з назвою our_products.
Малюнок 3

Останнім часом інвестиції принесли значний прибуток, тому треба обрати, куди саме вкласти гроші зараз. Ми отримали перелік компаній із їхніми товарами. Асортимент компаній знаходиться в множинах range_of_company_1, range_of_company_2 і range_of_company_3.
Та, як зрозуміти, у яку саме компанію вкладати гроші?
Звісно, в ту, асортимент якої збігається з нашими цільовими товарами. Тому, щоб отримати множину спільних товарів використаємо метод intersection():
our_products = {"Apple", "Tesla", "McDonald`s"}
range_of_the_company_1 = {"Samsung", "Sony"}
range_of_the_company_2 = {"Apple","IBM","Tesla"}
range_of_the_company_3 = {"BMW", "Tesla", "Ferrari"}
print(our_products.intersection(range_of_the_company_1))
print(our_products.intersection(range_of_the_company_2))
print(our_products.intersection(range_of_the_company_3))
Запустимо код (відео 8):
Відео 8
Як бачимо, найбільше збігів у нас з другою компанією, отже, саме в неїтреба інвестувати. Та може постати протилежне завдання - дізнатись, що мають додати компанії у свій асортимент, щоби зацікавити нас як інвесторів. Тоді скористаємось методом difference():
our_products = {"Apple", "Tesla", "McDonald`s"}
range_of_the_company_1 = {"Samsung", "Sony"}
range_of_the_company_2 = {"Apple","IBM","Tesla"}
range_of_the_company_3 = {"BMW", "Tesla", "Ferrari"}
print(our_products.difference(range_of_the_company_1))
print(our_products.difference(range_of_the_company_2))
print(our_products.difference(range_of_the_company_3))
Результат (відео 9):
Відео 9
Ми успішно інвестували, залишилося дізнатися розбіжності в товарах, для чого скористаємось методом symmetric_difference():
our_products = {"Apple", "Tesla", "McDonald`s"}
range_of_the_company_2 = {"Apple","IBM","Tesla"}
print(our_products.symmetric_difference(range_of_the_company_2))
Отримаємо (відео 10):
Відео 10
Але методи intersection(), difference() та symmetric_difference() не змінюють множин, з яких вони викликаються.
Тому є аналогічні за функціоналом методи, що можуть це робити:
- intersection_update() — залишає спільні елементи для двох множин (відео 11):
Відео 11
-
difference_update() — залишає елементи, яких нема в іншій множині (відео 12):
Відео 12
- symmetric_difference_update() — залишає унікальні елементи двох множин (відео 13):
Відео 13
Ми вже додавали до множин елементи, але, як їх прибрати звідти?
Допоможуть методи discard() і remove(), де всередину дужок передаємо елемент, що треба вилучити. Різниця між ними полягає в тому, що під час введення в перший метод елемента, що не існує, він відпрацює нормально, а другий спричинить помилку. Вилучимо рядки "Apple" і "McDonald`s" з асортименту. Додатково вилучимо рядок, що не існує "Mercedes":
our_products = {"Apple", "Tesla", "McDonald`s"}
our_products.discard("Apple")
our_products.discard("Mercedes")
print(our_products)
our_products.remove("McDonald`s")
print(our_products)
our_products.remove("Mercedes")
Результат (відео 14):
Відео 14
Аналогічно до списків, множини теж мають метод pop(). Та всередині множини елементи розташовуються в довільному порядку, отже, невідомо, який елемент буде виключено (відео 15):
Відео 15
Тому треба бути уважним користуючись цим методом (відео 16).
Відео 16
Як ми вже знаємо, незмінні типи даних створені для захисту від змін. Як множини, так і списки мають своїх «колег» із незмінюваним типом даних. Для множин нимє frozenset, а для списків — кортежі. Для обох типів даних доступні всі ті ж методи й функції, що і для їхніх змінюваних протеже, крім тих, які міняють дані.
Створимо frozenset і кортежі:
my_frozenset = frozenset()
print(type(my_frozenset))
my_tuple = tuple()
print(type(my_tuple))
my_tuple_2 = (0,)
print(type(my_tuple_2))
my_tuple_3 = 0,
print(type(my_tuple_3))
my_tuple_4 = (0)
print(type(my_tuple_4))
Результат (відео 17):
Відео 17
Як бачимо, тут ми створили frozenset і три кортежі, причому останні створювалися різними способами. Важливо, щоб під час створення frozenset всередину дужок передавалися ітеровані елементи або ж дужки мають бути пустими. В іншому випадку, Python повідомить про помилку. Ті ж вимоги діють і до кортежу, створеного першим способом.
Тепер зверни увагу на кортежі, створені другим і третім способами: за створення кортежів цими способами важливо передати принаймні один елемент, після якого обов'язково вказати кому. Натомість дужки не є обов'язковими. Якщо опустити кому й залишити дужки, побачимо, що Python не створить кортеж.
Сьогодні ми розглянули множини й розв'язали задачку для інвестора, познайомилися з frozenset та кортежами. А на наступному занятті нас чекає ще цікавіший і потужніший тип даних, який значно розширить наші можливості в Python.